My name is
Krzysztof Baron-Lis.
Lis
means
fox
in Polish.
I currently work on Sensor Simulation at
Waabi
- using
neural
rendering
methods
to simulate cameras and LiDARs to develop and test self-driving trucks.
I did my PhD at the EPFL
Computer Vision Lab
of Pascal Fua
where I researched detecting out-of-distribution (unusual) obstacles in road scenes.
I come from Poland and enjoy computer graphics, game development, fantasy & science-fiction.
Research
Capturing the Complexity of Spatially Varying Surfaces with Adaptive Parameterization and Distribution Metrics
Jessica Baron-Lis,
Krzysztof Baron-Lis
,
Eric Patterson
22nd ACM SIGGRAPH European Conference on Visual Media Production (CVMP 2025)
2025
Real-world materials, such as those desirable to render accurately in production, exhibit complex appearances that vary spatially across their surfaces. There are many works for estimating material-scattering properties, both for analytic and data-driven models, but common limitations of recent effort include the use of synthesized rather than measured data, reliance on neural networks that do not easily fit rendering pipelines, and not accounting for the spatially varying nature of light-scattering response over real surfaces.
We propose a pipeline for predicting, measuring, and rendering spatially varying appearances using a custom variable-illumination sphere with concepts that may be applied to other systems such as goniophotometers. We build on the adaptive-parameterization technique of Dupuy and Jakob, extending the ideas to support spatially varying material measurement. Focus is given to practical, efficient capture of varied scattering responses over a sample surface. Metrics and clustering techniques using data from an abbreviated initial capture are used to improve the efficiency of the full acquisition and material representation.
Our work introduces a novel approach to capture complex, spatially varying appearances more efficiently and also provides data for material and pattern analysis that may be used for rendering or other applications.
@inproceedings{baronlis2025capturing,
author = {Baron-Lis, Jessica and Baron-Lis, Krzysztof and Patterson, Eric},
title = {Capturing the Complexity of Spatially Varying Surfaces with Adaptive Parameterization and Distribution Metrics},
year = {2025},
isbn = {9798400721175},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3756863.3769711},
doi = {10.1145/3756863.3769711},
abstract = {Real-world materials, such as those desirable to render accurately in production, exhibit complex appearances that vary spatially across their surfaces. There are many works for estimating material-scattering properties, both for analytic and data-driven models, but common limitations of recent effort include the use of synthesized rather than measured data, reliance on neural networks that do not easily fit rendering pipelines, and not accounting for the spatially varying nature of light-scattering response over real surfaces.We propose a pipeline for predicting, measuring, and rendering spatially varying appearances using a custom variable-illumination sphere with concepts that may be applied to other systems such as goniophotometers. We build on the adaptive-parameterization technique of Dupuy and Jakob, extending the ideas to support spatially varying material measurement. Focus is given to practical, efficient capture of varied scattering responses over a sample surface. Metrics and clustering techniques using data from an abbreviated initial capture are used to improve the efficiency of the full acquisition and material representation.Our work introduces a novel approach to capture complex, spatially varying appearances more efficiently and also provides data for material and pattern analysis that may be used for rendering or other applications.},
booktitle = {Proceedings of the 22nd ACM SIGGRAPH European Conference on Visual Media Production},
articleno = {4},
numpages = {10},
keywords = {material acquisition, SVBRDF},
location = {
},
series = {CVMP '25}
}
SaLF: Sparse Local Fields for Multi-Sensor Rendering in Real-Time
Yun Chen,
Matthew Haines,
Jingkang Wang,
Krzysztof Baron-Lis
,
Sivabalan Manivasagam,
Ze Yang,
Raquel Urtasun
2025
SaLF (Sparse Local Fields) is a novel volumetric representation for autonomous driving sensor simulation that supports both rasterization and ray-tracing.
It represents scenes as sparse voxels containing local implicit fields, enabling efficient rendering of cameras (>30 FPS) and LiDARs (>400 FPS) with fast training times (<30 min) in RTX 3090.
Unlike existing neural rendering methods, SaLF uniquely combines advanced sensor modeling capabilities with superior computational efficiency while maintaining high visual fidelity across diverse environmental conditions and complex driving scenarios.
@article{
chen2025salf,
title={SaLF: Sparse Local Fields for Multi-Sensor Rendering in Real-Time},
author={Chen, Yun and Haines, Matthew and Wang, Jingkang and Baron-Lis, Krzysztof and Manivasagam, Sivabalan and Yang, Ze and Urtasun, Raquel},
booktitle={Arxiv},
year={2025},
}
AttEntropy: On the Generalization Ability of Supervised Semantic Segmentation Transformers to New Objects in New Domains
Krzysztof Baron-Lis
,
Matthias Rottmann,
Annika Mütze,
Sina Honari,
Pascal Fua,
Mathieu Salzmann
The 35th British Machine Vision Conference (BMVC)
2024
In addition to impressive performance, vision transformers have demonstrated remarkable abilities to encode information they were not trained to extract. For example, this information can be used to perform segmentation or single-view depth estimation even though the networks were only trained for image recognition. We show that a similar phenomenon occurs when explicitly training transformers for semantic segmentation in a supervised manner for a set of categories: Once trained, they provide valuable information even about categories absent from the training set and this information can be used to segment objects from these never-seen-before classes in domains as varied as road obstacles, aircraft parked at a terminal, lunar rocks, and maritime hazards.
@inproceedings{Baron-Lis_2024_BMVC,
author = {Krzysztof Baron-Lis and Matthias Rottmann and Annika Mütze and Sina Honari and Pascal Fua and Mathieu Salzmann},
title = {AttEntropy: On the Generalization Ability of Supervised Semantic Segmentation Transformers to New Objects in New Domains},
booktitle = {35th British Machine Vision Conference 2024, {BMVC} 2024, Glasgow, UK, November 25-28, 2024},
publisher = {BMVA},
year = {2024},
url = {https://papers.bmvc2024.org/0215.pdf}
}
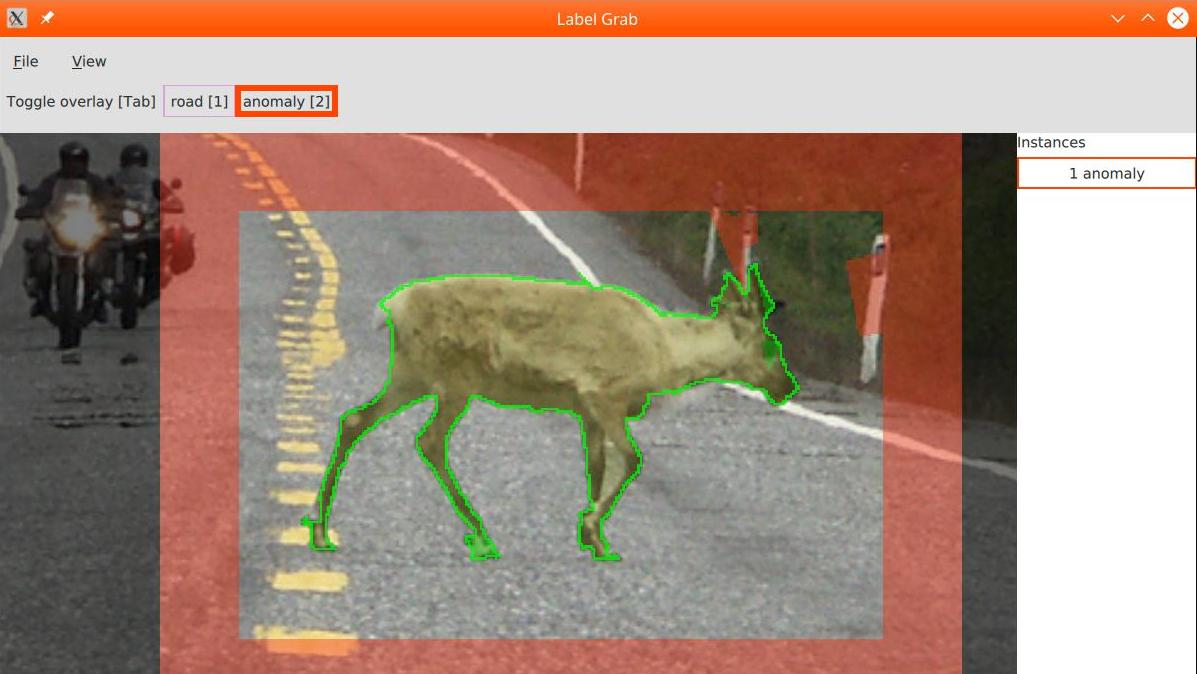
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Robin Chan,
Krzysztof Lis
,
Svenja Uhlemeyer,
Hermann Blum,
Sina Honari,
Roland Siegwart,
Pascal Fua,
Mathieu Salzmann,
Matthias Rottmann
NeurIPS 2021 Datasets and Benchmarks
2021
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects.
However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown.
We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several models specifically designed for anomaly / obstacle segmentation, on our datasets and on public ones, using our test suite.
The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and difficulty of both data landscapes.
@InProceedings{
SegmentMeIfYouCan,
title = \{\{SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation\}\},
author = {Robin Chan and Krzysztof Lis and Svenja Uhlemeyer and Hermann Blum and Sina Honari and Roland Siegwart and Pascal Fua and Mathieu Salzmann and Matthias Rottmann},
booktitle= {Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year = {2021},
url = {https://openreview.net/forum?id=OFiGmksrSz1}
}
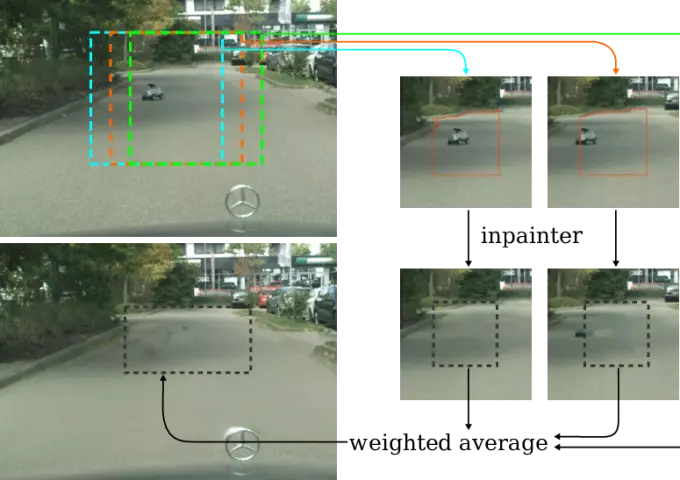
Detecting Road Obstacles by Erasing Them
Krzysztof Lis
,
Sina Honari,
Pascal Fua,
Mathieu Salzmann
TPAMI
2024
Vehicles can encounter a myriad of obstacles on the road, and it is impossible to record them all beforehand to train a detector. Instead, we select image patches and inpaint them with the surrounding road texture, which tends to remove obstacles from those patches. We then uses a network trained to recognize discrepancies between the original patch and the inpainted one, which signals an erased obstacle.
We also contribute a new dataset for monocular road obstacle detection, and show that our approach outperforms the state-of-the-art methods on both our new dataset and the standard Fishyscapes Lost \& Found benchmark.
Detecting the Unexpected via Image Resynthesis
Krzysztof Lis
,
Krishna Nakka,
Pascal Fua,
Mathieu Salzmann
ICCV
2019
Classical semantic segmentation methods, including the recent deep learning ones, assume that all classes observed at test time have been seen during training.
In this paper, we tackle the more realistic scenario where unexpected objects of unknown classes can appear at test time.
The main trends in this area either leverage the notion of prediction uncertainty to flag the regions with low confidence as unknown, or rely on autoencoders and highlight poorly-decoded regions.
Having observed that, in both cases, the detected regions typically do not correspond to unexpected objects, in this paper, we introduce a drastically different strategy:
It relies on the intuition that the network will produce spurious labels in regions depicting unexpected objects.
Therefore, resynthesizing the image from the resulting semantic map will yield significant appearance differences with respect to the input image.
In other words, we translate the problem of detecting unknown classes to one of identifying poorly-resynthesized image regions.
We show that this outperforms both uncertainty- and autoencoder-based methods.
@InProceedings{Lis_2019_ICCV,
author = {Lis, Krzysztof and Nakka, Krishna and Fua, Pascal and Salzmann, Mathieu},
title = {Detecting the Unexpected via Image Resynthesis},
booktitle = {IEEE International Conference on Computer Vision (ICCV)},
month = {October},
year = {2019},
url = {https://infoscience.epfl.ch/record/269093?ln=en}
}
Geometric and Physical Constraints for Drone-Based Head Plane Crowd Density Estimation
Weizhe Liu,
Krzysztof Lis
,
Mathieu Salzmann,
Pascal Fua
IROS
2019
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density in the image plane.
While useful for this purpose, this image- plane density has no immediate physical meaning because it is subject to perspective distortion.
This is a concern in sequences acquired by drones because the viewpoint changes often.
This distortion is usually handled implicitly by either learning scale- invariant features or estimating density in patches of different sizes, neither of which accounts for the fact that scale changes must be consistent over the whole scene.
In this paper, we explicitly model the scale changes and reason in terms of people per square-meter.
We show that feeding the perspective model to the network allows us to enforce global scale consistency and that this model can be obtained on the fly from the drone sensors.
In addition, it also enables us to enforce physically-inspired temporal consistency constraints that do not have to be learned.
This yields an algorithm that outperforms state-of-the-art methods in inferring crowd density from a moving drone camera especially when perspective effects are strong.
@article{head_plane_crowd_density_2018,
title={Geometric and Physical Constraints for Drone-Based Head Plane Crowd Density Estimation},
author = {Weizhe Liu and Krzysztof Lis and Mathieu Salzmann and Pascal Fua},
journal = {IROS},
year={2019}
url = {https://infoscience.epfl.ch/record/268343}
}
The algorithm attempts to find the foreground object in a user-selected bounding box.
It presents a suggested per-pixel mask, the user can then correct its mistakes and next suggestion
will take those into account.
Augmented Unreality
Augmented Unreality is a plugin for
Unreal Engine 4
which enables creation of augmented reality applications
by displaying a video stream from a camera inside the game
and tracking camera position using the
ArUco fiducial markers
.
I created it as a semester project at ETH Zürich.
Comparing Python, Go, and C++ on the N-Queens Problem
Using the XML-native database BaseX to process big XML data.
LaTeX cleaner
A tool for preparing LaTeX sources for submission to ArXiv.
Kubernetes Job Dashboard
Web dashboard for jobs running on EPFL’s Kubernetes cluster for my and others labs. Lists pods per user, the number of GPUs allocated, GPU memory and compute utilization. The backend is using an async Python HTTP server aiohttp and interfacing with the Kubernetes API. The frontend web-application uses Preact.
Conquering a 5 GiB XML file with XML-native databases
Using the XML-native database BaseX to process big XML data.